8 April 2026 · 15 min read · By Mark Laursen
1-Bit LLMs Could Make GPUs Obsolete (And Why Nobody Is Betting on It Yet)
NVIDIA is worth over $3 trillion. That valuation rests on one assumption: AI requires GPUs.
In April 2025, Microsoft Research released BitNet b1.58 2B4T, a language model trained entirely on weights that can only be {-1, 0, 1}. It matched full-precision models on reasoning benchmarks while using 12 times less energy and fitting in 400 megabytes of memory. It runs on a CPU.
By early 2026, the bitnet.cpp inference framework hit #1 trending on GitHub with over 25,000 stars as of March 2026. The headline benchmark: a simulated 100-billion parameter BitNet model running on a single consumer CPU at 5 to 7 tokens per second, roughly human reading speed. The largest natively-trained model publicly available is still 8 billion parameters, but the inference framework demonstrates that the computational pattern scales.
I have been tracking this research since the original BitNet paper in early 2024, and I ran bitnet.cpp on my own hardware when the 2B model dropped. Watching a language model run at interactive speed on a CPU, with no GPU, no cloud, no special hardware, reframes how you think about the economics of AI infrastructure.
To be clear: this is an inference story, not a training story. Nobody is suggesting 1-bit models will replace GPU clusters for training frontier models. The question is narrower and more immediate: whether enough inference demand can move off GPUs to reshape the economics of serving AI at scale. This post covers the research, what it means for the companies building AI hardware, and why the path from here is more uncertain than either the hype or the skepticism suggests.
What Are 1-Bit LLMs and How Do They Work?
The name is slightly misleading. “1-bit” does not mean binary. BitNet b1.58 uses ternary weights: every parameter in the model is one of three values: {-1, 0, 1}. The “1.58” comes from information theory: log2(3) = 1.58 bits, the amount of information stored per weight.
This is a fundamental architectural change, not a compression trick. Traditional LLMs store weights as 16-bit or 32-bit floating-point numbers. Post-training quantization compresses those numbers down to 8-bit or 4-bit integers, trading some accuracy for efficiency. BitNet does something different: it trains natively at 1.58 bits. The model never had full-precision weights to begin with.
| Traditional (FP16) | 1-Bit (Ternary) | |
|---|---|---|
| Bits per weight | 16 | 1.58 |
| Dominant operation | Multiply + accumulate | Add + subtract |
| Hardware required | GPU parallelism | Any CPU |
The computational implication is what matters. In a traditional LLM, the dominant operation is matrix multiplication: multiply a weight by an activation, accumulate the result. This is what GPUs excel at, thousands of floating-point multiply-accumulate operations in parallel.
With ternary weights, there is no multiplication. A weight of 1 means “add the activation.” A weight of -1 means “subtract the activation.” A weight of 0 means “skip.” The entire forward pass becomes addition and subtraction. CPUs can do addition and subtraction. They always could.
How Does BitNet b1.58 Perform Against Full-Precision Models?
The BitNet b1.58 2B4T technical report published hard benchmarks against full-precision models of equivalent size. The results are not “close enough for a compressed model.” They are competitive, and in some cases better.
| Metric | BitNet b1.58 (2B) | Qwen2.5 FP16 (2B) | Difference |
|---|---|---|---|
| GSM8K (math) | 58.38 | 56.79 | +1.59 |
| WinoGrande (reasoning) | 71.90 | 62.83 | +9.07 |
| Memory footprint | 0.4 GB | 1.4-4.8 GB | 3.5-12x smaller |
| Energy per inference | 0.028 J | 0.347 J | 12x less |
On mathematical reasoning (GSM8K), BitNet scored 58.38 against Qwen2.5’s 56.79. On commonsense reasoning (WinoGrande), it scored 71.90 against 62.83. The memory footprint: 0.4 GB versus 1.4 to 4.8 GB. Energy per inference: 0.028 joules versus 0.347 joules, roughly 12 times more efficient.
The inference framework bitnet.cpp achieved speedups of 2.37x to 6.17x on x86 CPUs, with energy reductions between 55% and 82%. A January 2026 optimization pass added another 1.15x to 2.1x on top of that.
These are not marginal improvements. This is a different cost curve.
Why Do 1-Bit LLMs Threaten NVIDIA’s Position?
NVIDIA’s dominance in AI is not about GPUs being fast. It is about GPUs being the only hardware that can do the specific math AI requires at the scale AI requires it. The entire value proposition is parallel floating-point matrix multiplication. CUDA, the software ecosystem that locks developers into NVIDIA hardware, exists to make that specific operation as efficient as possible.
1-bit LLMs remove that operation from the equation.
When every weight is {-1, 0, 1}, inference becomes addition and subtraction. There is no matrix multiplication. The computational bottleneck that justified $40,000 GPUs dissolves. A CPU, the chip already in every computer, server, and phone on earth, can handle the arithmetic.
This matters because the inference market is already larger than the training market. The vast majority of compute spent on AI is not training new models. It is running existing models, generating tokens, answering questions, writing code, processing requests. Every token ChatGPT generates is an inference operation. Every coding assistant suggestion, every search summary, every agent action.
NVIDIA’s data center revenue exceeded $47 billion in fiscal 2025. Training will continue to require GPU-class hardware for the foreseeable future. But the inference share of that revenue, which is growing faster than training, is the vulnerable slice. If inference migrates to CPUs, that portion is at risk. Not because someone built a better GPU, but because the GPU becomes unnecessary for the workload that generates the most tokens.
The early signals are already visible. Meta has deployed millions of NVIDIA Grace CPUs, NVIDIA’s own ARM-based processor, for agentic workloads where cost per token matters more than peak throughput. The irony is telling: even NVIDIA’s product lineup now includes a CPU designed for inference workloads that do not need GPU-class parallelism. An industry analysis from 2025 found that for models under 3 billion parameters, multi-threaded CPU execution achieves 1.31x speedups over GPU execution. The crossover point is moving upward as 1-bit models scale.
This also matters for multi-agent AI systems, where inference cost compounds with every agent in the pipeline. If you are running three to four specialist agents per task, each generating thousands of tokens, the difference between GPU-priced inference and CPU-priced inference is the difference between a viable product and an unsustainable burn rate. And when those agents hold real API credentials and make real API calls, every token they generate carries both a cost and a risk. Cheaper inference does not just save money; it makes the entire agent ecosystem more practical to deploy and govern.
AMD and Intel’s Once-in-a-Decade Opening
Here is the irony. AMD and Intel have spent years trying to compete with NVIDIA on GPUs and losing. AMD’s ROCm software stack has been perpetually “almost there.” Intel’s Arc GPUs and Ponte Vecchio accelerators have been commercial disappointments. NVIDIA’s CUDA ecosystem is a software moat deeper than any hardware advantage either company can build.
If the inference thesis holds, 1-bit LLMs would let them win by making GPUs irrelevant for serving models.
AMD and Intel already own the CPU market. In a scenario where inference becomes CPU-native, the competitive landscape inverts. The companies that have been losing the AI hardware race would suddenly own the hardware that matters most for the fastest-growing segment of AI compute.
Both companies know this. Intel is building 1-bit and 2-bit microkernels optimized for modern CPUs, leveraging their AMX (Advanced Matrix Extensions) instruction sets. Their Panther Lake chips, announced at CES 2026, ship with 50 TOPS NPUs and 180 total platform TOPS across CPU, GPU, and NPU. Intel is quietly building the silicon that would benefit most from a 1-bit future.
AMD is moving in the same direction. Their Ryzen AI NPUs and Quark quantization toolchain target low-bit inference on edge devices. An AMD blog post from 2026 is titled, without subtlety: “Agentic AI Brings New Attention to CPUs in the AI Data Center.”
The hardware investment is real. But neither company is going all-in. And there is a reason for that.
What Is the Biggest Risk Holding Back 1-Bit LLM Adoption?
The largest risk facing 1-bit LLMs has nothing to do with whether the models work. The risk is architectural.
Every 1-bit optimization, every ternary microkernel, every CPU instruction set extension, is built on one assumption: that the transformer is the right architecture for language models. If you optimize your entire hardware pipeline for ternary transformer inference and the field moves to a different architecture, your investment is stranded.
This is not a theoretical concern. The transformer’s dominance is being actively challenged on multiple fronts.
Diffusion language models treat text generation as denoising rather than sequential token prediction. LLaDA, an 8-billion parameter diffusion LLM, matches Llama 3 8B on standard benchmarks and solves the “reversal curse” that plagues autoregressive models, outperforming GPT-4o on reversal tasks. Gemini Diffusion hit 1,479 tokens per second. Over 50 papers on diffusion LLMs appeared in 2025 alone. The core advantage: generating multiple tokens in parallel rather than one at a time.
State space models like Mamba process sequences in linear time rather than the quadratic time of attention mechanisms. They have reached parity with transformers on key benchmarks and surpassed them on long-context tasks.
Hybrid architectures are already in production. Jamba interleaves transformer layers with state-space layers and mixture-of-experts routing. Over 60% of frontier models released in 2025 used mixture-of-experts. The pure transformer may already be fading.
If diffusion models become the dominant paradigm, the computational profile changes completely. Diffusion models have different memory access patterns, different parallelism requirements, different bottlenecks. Hardware optimized for ternary transformer inference would miss the target.
This is likely the actual reason AMD and Intel are not betting everything on 1-bit: the software architecture has not stabilized. The transformer has been dominant since 2017, but nine years is a short time in hardware investment cycles. If you are committing billions to silicon design with a 3 to 5 year production timeline, you need confidence that the architecture you are optimizing for will still be the right one when the chips ship.
The historical parallel is instructive. Imagine optimizing hardware for recurrent neural networks in 2015. Two years later, “Attention Is All You Need” made RNNs obsolete overnight. Any hardware optimized for RNN-specific operations would have been a dead investment.
The Three Futures
Scenario A: 1-bit scales, transformers hold. CPUs eat the inference market. NVIDIA retreats to training and gaming. AMD and Intel, who have been losing the GPU war for a decade, suddenly own the most important hardware in AI. GPUs go back to being what they started as: graphics cards for video games.
Scenario B: Architecture shifts. Diffusion models, state space models, or some hybrid becomes the dominant paradigm. Every current hardware optimization, whether for GPUs, 1-bit CPUs, or custom ASICs, targets the wrong architecture. The winner is whoever can retool fastest. This is the nightmare scenario for anyone making billion-dollar silicon bets today.
Scenario C: NVIDIA adapts. They have done it before. NVIDIA pivoted from gaming to crypto mining to AI training to AI inference. If 1-bit inference becomes the standard, NVIDIA builds optimized silicon for it or acquires the capability. The CUDA ecosystem adapts. The moat holds.
The largest constraint on all three scenarios: the biggest natively-trained 1-bit model publicly available as of early 2026 is 8 billion parameters. Frontier models are 70B and above. The scaling question is open. Microsoft Research is actively working on it, but “works at 2B” and “works at 200B” are different claims with different evidence requirements.
What Milestones Will Determine Whether 1-Bit LLMs Go Mainstream?
Four milestones will determine which scenario plays out.
A 70B+ native 1-bit model that matches frontier performance. The largest published model is 8B. Scaling to 70B or above while maintaining competitive benchmarks is the existence proof. Until it happens, 1-bit LLMs are a compelling result for small and medium models, not a proven replacement for frontier inference.
Intel or AMD shipping CPU instructions explicitly optimized for ternary operations. Both companies are investing in low-bit integer math, but dedicated ternary support would signal serious commitment to a 1-bit future rather than hedged positioning.
A major cloud provider offering CPU-based 1-bit inference as a pricing tier. When AWS or Azure prices it as a cheaper alternative to GPU inference, the market will form around it. Pricing is the signal that matters more than benchmarks.
A non-transformer architecture achieving frontier performance. If diffusion LLMs or state space models produce a GPT-4 class competitor, the hardware optimization landscape reshuffles overnight. This is the event that would vindicate the caution of every company not going all-in on 1-bit today.
Run the Numbers Yourself
How much would 1-bit inference actually save on your workloads? Adjust the model size and daily request volume to see the GPU vs CPU cost comparison.
This is a simplified model: pricing assumes A100 at $2/hr and CPU instances at $0.40/hr with estimated throughput scaling. For the full interactive version with deployment options, scenario analysis, and a guided decision tree:
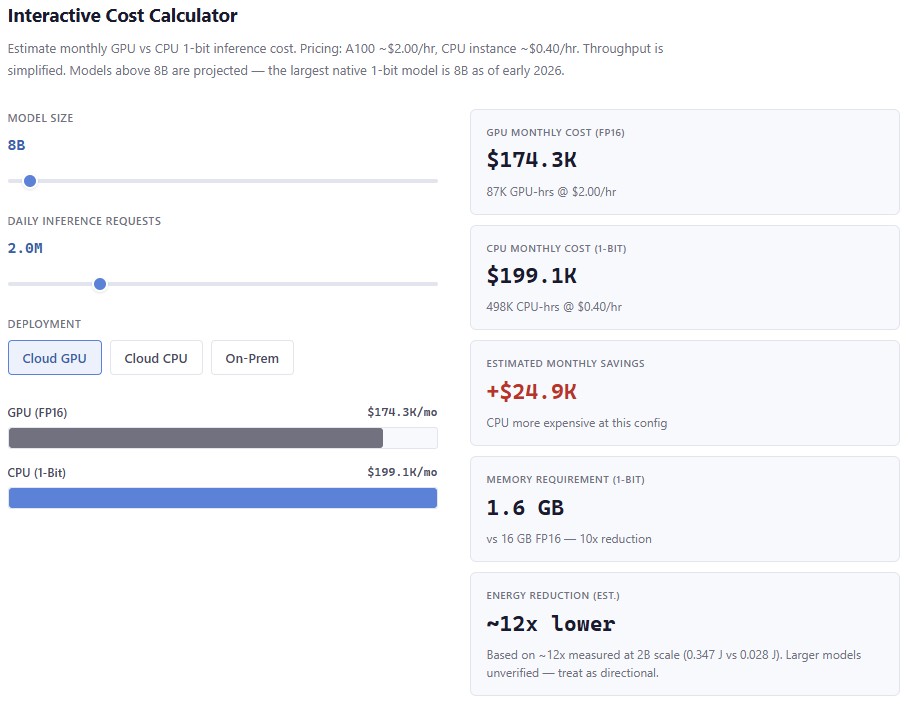
Open the full interactive decision framework →
What This Reveals
The most interesting thing about 1-bit LLMs is not the technology. It is what they reveal about the fragility of the current AI hardware landscape.
NVIDIA’s position looks unassailable from the outside. 92% market share in discrete GPUs. A software ecosystem that locks in developers. Revenue growth that defies gravity. But that dominance is built on one specific computational pattern: parallel floating-point matrix multiplication. If that pattern becomes unnecessary, the moat drains, regardless of how deep it is.
This connects to a broader pattern in AI infrastructure. Just as multi-agent systems fail from coordination overhead rather than model capability, the AI hardware market may fail from architectural assumptions rather than engineering limitations. The bottleneck is not building faster chips. It is knowing which chips to build.
The 1-bit research is real. The benchmarks are published. The inference framework is open source. The CPU advantage is measurable. What remains unproven is whether it scales to the sizes that matter. And whether the architecture it optimizes for will still be the right one when it does.
The math is simple. The bet is not.
Frequently Asked Questions
What makes 1-bit LLMs fundamentally different from quantized models?
Post-training quantization compresses existing full-precision weights down to 8-bit or 4-bit integers. BitNet b1.58 trains natively at 1.58 bits per weight, meaning the model never had full-precision weights to begin with. That is an architectural change, not a compression trick. The result is that the forward pass becomes addition and subtraction rather than floating-point matrix multiplication, which is the operation that requires GPU hardware.
How large is the biggest natively-trained 1-bit model available today?
As of early 2026, the largest publicly available natively-trained 1-bit model is 8 billion parameters. Frontier models run at 70 billion parameters and above. The bitnet.cpp inference framework has simulated a 100-billion parameter model on a single consumer CPU at 5 to 7 tokens per second, which demonstrates the computational pattern can scale, but simulated results are not the same as a model trained natively at that size.
Why might AMD and Intel benefit more from 1-bit LLMs than NVIDIA?
NVIDIA’s value is tied to parallel floating-point matrix multiplication, which GPUs do well. If inference shifts to ternary weight arithmetic, that operation disappears from the workload. AMD and Intel already own the CPU market, so a world where inference runs on CPUs is a world where they own the most important hardware for the fastest-growing segment of AI compute. That is why AMD titled a 2026 blog post “Agentic AI Brings New Attention to CPUs in the AI Data Center.”
What happens to 1-bit LLM investments if transformers stop being the dominant architecture?
Every ternary microkernel and CPU instruction set extension built for 1-bit inference assumes transformers remain the right architecture. If diffusion language models or state-space models like Mamba become dominant, the computational profile changes: different memory access patterns, different parallelism requirements, different bottlenecks. Hardware optimized specifically for ternary transformer inference would become a stranded investment. This is the same risk Intel would have faced if it had optimized silicon for recurrent neural networks in 2015 and then “Attention Is All You Need” shipped two years later.
Disclosure: I have no financial position in NVIDIA, AMD, or Intel. I build open-source AI orchestration tools and agent governance infrastructure, both of which would benefit from cheaper inference regardless of which hardware provides it.

Advisor, founder, and executive producer with 25+ years building technology companies, gaming platforms, and entertainment products. Based in Portugal.