15 April 2026 · 13 min read · By Mark Laursen
AI Is Running Out of Power, Data, and Quality All at Once
In Season 3 of Silicon Valley, Gavin Belson stands in front of a Hooli board meeting and delivers a warning:
“Data creation is exploding. With all the selfies and useless files people refuse to delete on the cloud, 92 percent of the world’s data was created in the last two years alone. At the current rate, the world’s data storage capacity will be overtaken by next spring. It will be nothing short of a catastrophe. Data shortages. Data rationing. Data black markets.”
That was comedy in 2016. In 2026, the numbers are worse than the joke.
The world will generate over 230 zettabytes of data this year. Global data center electricity consumption will hit 1,100 terawatt-hours, equivalent to Japan’s entire national electricity usage. And according to Epoch AI, the stock of human-generated text available for training may already be effectively exhausted.
Gavin Belson warned about storage. The actual crisis is worse: AI is running out of power, data, and quality at the same time. And the three problems are connected in a way that makes each one harder to solve.
How Is the Power Crisis Limiting AI Growth?
A single AI query consumes roughly 1,000 times more electricity than a traditional web search. A hyperscale AI data center requires 100 to 300 megawatts of continuous power, the equivalent of a mid-sized city. As of 2026, nearly 50% of all global data center projects scheduled for completion this year face delays directly attributable to power supply limits.
The constraint is not money. The five major hyperscalers plan to spend roughly $660 to $690 billion on infrastructure in 2026, most of it directed at AI. The constraint is physics. Power grids cannot be upgraded at the speed AI demand is growing. AI technology scales exponentially; transmission lines, substations, and power plants operate on decade-long construction cycles.
The result is already showing up in electricity bills. In Virginia, where data centers consume one in every five kilowatt-hours produced by the state’s largest utility, residential customers are paying for the infrastructure expansion. Retail electricity prices across the US have risen 42 percent since 2019, outpacing inflation. Goldman Sachs projects that data center power consumption will add 0.1 percent to core inflation in both 2026 and 2027.
Over 60% of the power feeding US data centers still comes from fossil fuels, despite every major hyperscaler’s carbon-neutral pledge. The AI industry’s stated climate goals and its actual energy trajectory are moving in opposite directions.
Why Is AI Running Out of Training Data?
In parallel with the power crisis, AI is running into a more fundamental problem: the raw material it learns from is finite.
Epoch AI’s research estimates that the stock of high-quality human-generated text on the internet could be effectively exhausted as training data between 2026 and 2032, with a real possibility it has already happened. A February 2026 article in Communications of the ACM observed that the web corpus that fed GPT-3, GPT-4, LLaMA, and DeepSeek is “long exhausted.”
The instinct is to generate more data synthetically: use AI to create the training data for the next generation of AI. This is where the feedback loop begins.
A 2024 Nature study demonstrated that AI models trained on output from other AI models progressively degrade until they collapse. The outputs become less diverse, less creative, and less accurate with each generation. The technical term is model collapse, and it is not a theoretical risk. As of 2025, approximately 74% of newly published web pages contain AI-generated material. The training pool is already contaminated.
The nuance matters here. The risk is not synthetic data itself; it is undiscriminating use of synthetic data. Andrej Karpathy’s recent work on LLM Knowledge Bases demonstrates a curated approach: an LLM compiles raw information into a living wiki, runs health checks to find inconsistencies, discovers connections between topics, and refines the data through continuous linting. As the knowledge base grows purer, it becomes a high-quality training set. The key difference is curation. Karpathy’s pipeline has an LLM discovering and organizing knowledge with human oversight, not blindly regurgitating its own outputs back into training. That distinction separates useful synthetic data from the kind that causes collapse.
The broader problem remains, though. Most of the AI-generated content flooding the web is not curated. It is raw model output published at scale. And that is what future models will inadvertently train on. The snake is eating its own tail, and most of what it is swallowing is junk.
Why Are AI Models Degrading Despite Better Benchmark Scores?
If you have used frontier AI models consistently over the past year, you have probably noticed something: they feel different. Not always worse on benchmarks, but less reliable, less sharp, more prone to hedging and filler.
The data supports the intuition. A detailed analysis of 6,852 Claude Code sessions spanning January through March 2026 found that the model consumed 80x more API requests and 64x more output tokens to produce demonstrably worse results on complex engineering tasks. This was not a subtle decline. It was a measurable regression across thousands of sessions.
The broader pattern is consistent. Research shows that 91% of machine learning models degrade over time. Frontier models have saturated standard benchmarks above 88%, which means the benchmarks can no longer distinguish between models that feel meaningfully different to users. A model can score higher on MMLU while producing outputs that practitioners find less useful.
Some of this is economic. Providers face pressure to serve more users at lower cost, which means routing more queries to smaller, cheaper models or aggressively compressing context windows. Some of it is technical: context rot, where model performance degrades continuously as input length grows, affects every frontier model tested, including those advertising 200K token windows. And some of it is the model collapse feedback loop: models trained on increasingly AI-contaminated data produce increasingly generic output.
The result is a strange moment where AI is simultaneously more capable on paper and less reliable in practice.
The Trilemma
These three crises are not independent. They form a feedback loop where solving one problem makes another worse.
Want better quality? Train on more data for longer. That burns more power and accelerates the energy crisis.
Running out of human data? Generate synthetic data. That feeds the model collapse loop and degrades quality.
Need to reduce power consumption? Quantize models to lower precision or use smaller architectures. That trades quality for efficiency.
Need to serve more users cheaply? Route to smaller models or compress context. That degrades the user experience and feeds the perception that models are getting worse.
Every lever pulls against another. This is not a problem that more investment solves by itself. The five hyperscalers are spending $690 billion on infrastructure this year. If the constraints were purely financial, they would already be solved.
What Can Actually Solve the AI Power, Data, and Quality Crisis?
This is not an unsolvable problem. But the solutions look different from what the industry is currently doing. The way out is not scaling harder. It is scaling smarter.
1-bit architectures are the most promising efficiency breakthrough on the horizon. Microsoft’s BitNet b1.58 replaces floating-point matrix multiplication with simple addition and subtraction, achieving 12x energy efficiency improvements while matching full-precision model quality. If 1-bit models scale to frontier sizes, the power wall becomes dramatically less steep. A 100-billion parameter model running on a CPU at human reading speed is not a thought experiment; it is a published result.
Smaller, task-specific models outperform general-purpose giants for most real workloads. A 2-billion parameter model fine-tuned for code review will beat a 70-billion parameter general model on code review, at a fraction of the compute. The industry’s fixation on building ever-larger general models is partly a marketing race, not a technical necessity. Most production AI workloads do not need a model that can write poetry, pass the bar exam, and generate SQL. They need a model that does one thing extremely well.
Sparse architectures and mixture-of-experts reduce active compute without reducing model capacity. Over 60% of frontier models released in 2025 use mixture-of-experts, where only a fraction of the model’s parameters activate for any given input. A 400-billion parameter MoE model might only use 50 billion parameters per query, giving you the capacity of a massive model at the inference cost of a much smaller one.
Retrieval-augmented generation replaces memorization with lookup. Instead of training a model to memorize every fact (which requires enormous data and compute), you give it access to an external knowledge base and let it look things up. This reduces training data requirements, keeps information current without retraining, and produces more accurate, verifiable outputs. It does not eliminate the need for training data, but it reduces the pressure on the data wall significantly.
Edge and local inference distribute the power load. Instead of routing every query to a hyperscale data center, 1-bit models running on local CPUs can handle a meaningful share of inference workloads. This does not eliminate data center demand, but it takes the peak off, the same way rooftop solar does not replace the grid but reduces the strain on it.
How much difference do these approaches actually make? This interactive calculator lets you estimate the power, cost, and carbon footprint of your AI workloads, then toggle each efficiency approach to see the impact:
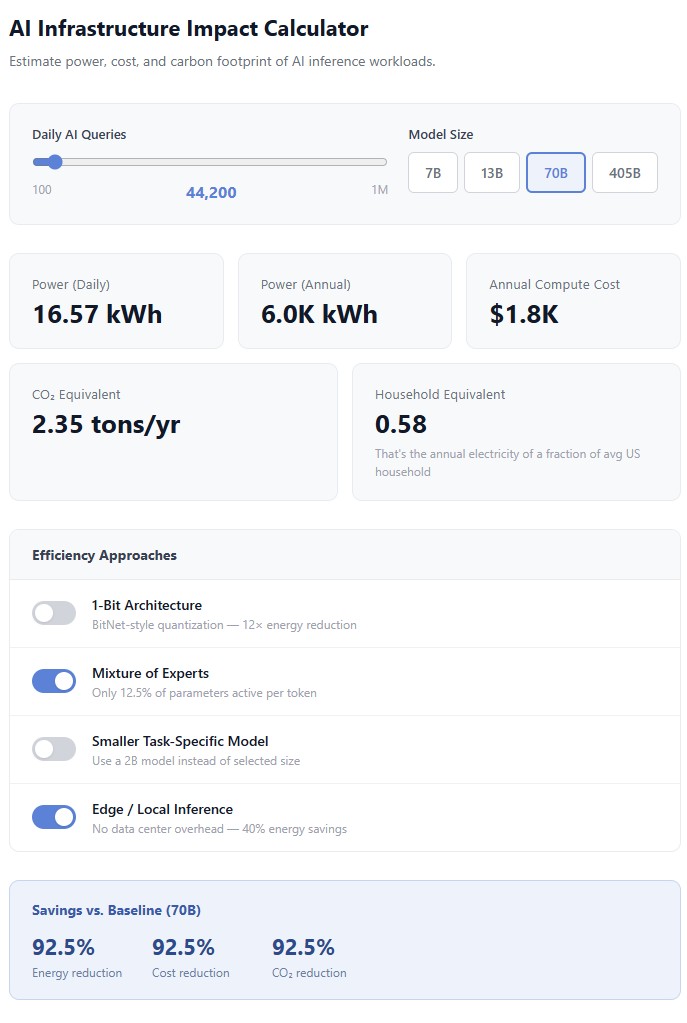
Open the full interactive calculator →
None of these are silver bullets. Each comes with trade-offs: 1-bit scaling is unproven past 8B parameters, fine-tuned models require domain expertise to build, MoE adds routing complexity, RAG introduces retrieval latency, and edge inference only works for models small enough to run locally. But collectively, they represent a fundamentally different approach: instead of building bigger models and bigger data centers to run them, make the models smaller, more efficient, and more targeted.
The era of “scale solves everything” is running into the physical limits of power grids, the information-theoretic limits of available training data, and the thermodynamic limits of cramming more computation into data centers. What comes next will not look like a bigger version of what we have now.
What to Watch
The first 70B+ native 1-bit model. This is the existence proof that efficiency and quality can coexist at frontier scale. Until it ships, 1-bit remains a promising result at small and medium scale.
Data center project completion rates. Currently 50% face delays from power constraints. If that number climbs, it signals that the infrastructure buildout cannot keep pace with demand, regardless of how much capital is available.
Training data provenance tooling. The ability to distinguish human-generated from AI-generated text in training corpora is critical to preventing model collapse. Watermarking and provenance standards are in early stages, but they will determine whether synthetic data can be safely used or whether it remains a poison pill.
The ratio of model quality to model size. If a 2B parameter model in 2027 outperforms a 70B model from 2025 on real-world tasks, the scaling paradigm has shifted. Watch for papers where smaller models win, not through cherry-picked benchmarks, but on production workloads.
Your electricity bill. This is the most tangible leading indicator. When AI infrastructure costs show up in household utility bills, the political and regulatory response will follow. That response will shape which data center projects get built and where.
The Bigger Picture
Gavin Belson’s warning in Silicon Valley was played for laughs because the crisis he described was absurd. The 2026 version of that crisis is not absurd. It is the subject of IEA reports, Pew Research studies, and $690 billion in capital expenditure.
The AI industry’s current trajectory assumes that scaling up, bigger models, more data, more compute, is the path forward. The evidence suggests we are approaching the limits of that assumption on multiple fronts simultaneously. Power grids cannot grow fast enough. Human training data is finite. Model quality degrades through the feedback loops that scaling creates.
The companies and researchers working on efficiency, on doing more with less, on making AI lighter rather than heavier, are building for the world that is actually arriving. The ones still planning to scale their way out of these constraints are building for a world that may not exist.
The question is not whether AI has a future. It does. The question is whether that future looks like today’s approach at 10x scale, or something fundamentally different. The walls are real. The math says different.
Frequently Asked Questions
How much electricity do AI data centers use compared to other countries?
Global data center electricity consumption will hit 1,100 terawatt-hours in 2026, equivalent to Japan’s entire national electricity usage. That is up from 460 TWh in 2022, a jump driven almost entirely by AI workloads. A single hyperscale AI data center requires 100 to 300 megawatts of continuous power, and nearly 50% of global data center projects scheduled for completion this year face delays because power supply cannot keep up.
What is model collapse, and is it already happening?
Model collapse is what happens when AI models train on output generated by other AI models. A 2024 Nature study demonstrated that each successive generation becomes less diverse, less creative, and less accurate until the model’s outputs degrade to near-uselessness. It is not theoretical: as of 2025, approximately 74% of newly published web pages contain AI-generated material, which means the training pool is already contaminated. The risk is not synthetic data itself but undiscriminating use of it — curated pipelines like Andrej Karpathy’s LLM Knowledge Base work are a meaningful exception.
Why can’t the AI industry just spend more money to fix these problems?
The five major hyperscalers plan to spend $660 to $690 billion on infrastructure in 2026. The constraints are not financial. Power grids operate on decade-long construction cycles and cannot be upgraded at the speed AI demand is growing. Human-generated training text is finite by definition; no amount of money creates more of it. And model quality degradation is a feedback loop problem, not a capital problem. More investment accelerates the same dynamics that are already creating the crises.
What is the most promising way to reduce AI energy consumption?
Microsoft’s BitNet b1.58 replaces floating-point matrix multiplication with addition and subtraction, achieving 12x energy efficiency improvements while matching full-precision model quality at 2 billion parameters. If 1-bit architectures scale to frontier sizes, the power wall becomes significantly less steep. Mixture-of-experts is also worth watching: over 60% of frontier models released in 2025 use it, activating only a fraction of parameters per query and cutting inference compute without reducing model capacity.
Disclosure: I build open-source AI orchestration tools and agent governance infrastructure that benefit from more efficient inference. My interest in this topic is both analytical and practical.

Advisor, founder, and executive producer with 25+ years building technology companies, gaming platforms, and entertainment products. Based in Portugal.